Description¶
This guideline describes how to create, generate and deploy Bonseyes AI Apps given a pre-trained AI model. This guideline assumes you already have the done the following:
Setup the local environment as explained in Prerequisites
Trained an AI model and exported such model in ONNX format. For more information about training and exporting models, refer to the AI Asset guideline.
Have followed AI App user guide description and got familiar with LPDNN.
Make sure to install system package
hdf5-toolsand pythonh5py.
Create LPDNN’s file tree¶
To generate and deploy AI Apps, a file tree with certain format needs to be created:
challenge/ catalog/ deployment/ deployment_packages/
where
Challenge: Folder containing the specifications of the AI Challenge that the AI App aims to solve.
Catalog: Folder containing pre-trained AI models.
Deployment: Folder containing the AI App’s deployment characteristics.
Deployment packages: Folder containing packages that contain tools, executables, libraries and backends that allows the actual execution of the LPDNN AI application.
A template with this organization is available in the AI Asset Container Generator.
An example with LPDNN tree file is also available in the 3D Face Landmarks AI Asset.
In the following sections, each of this folders is detailed and described.
Challenge¶
To create an LPDNN AI Challenge for you AI App, please follow the dev guide for AI Challenge’s Creating the LPDNN challenge and creation.
Note: the following steps can be skipped for the moment:
Defining the challenge training and sample data (Deprecated),
Defining the evaluation procedure (Deprecated)
Upload Challenge.
After having followed the creation of the AI Challenge, the LPDNN’s file tree challenge/ directory must include the following files:
challenge.yml
classes.txt (if required by challenge interface)
landmarks.txt (if required by challenge interface)
Catalog¶
The catalog is a folder that contains AI models:
catalog/
${modelName-version-size-precision}/
${modelName-version-size-precision}/
${modelName-version-size-precision}/
where ${ModelNameVersionSizePrecision} is the name of the model, with the specific version, input tile size and precision.
LPDNN expects AI models in a certain format and organization:
${modelName-version-size-precision}/ algorith.yml model.yml blobs/ ${modelName-version-size-precision}.onnx
where:
algorith.yml: YML file that describes the AI model’s type of algorithm or class, e.g., image classification, the challenge that it tries to solve and the pre-, inference, and post-processing details.
model.yml: YML file that describes the format of the AI model, e.g., ONNX, and the path to the model.
blobs: Folder that holds the trained AI model(s).
${modelName-version-size-precision}.onnx: Pre-trained model file(s) following the model naming explained above.
model.yml¶
The model.yml file is a simple YAML file that provides metadata required to consume an AI model in one of the supported model file formats. It has the following structure:
type: com_bonseyes/network_formats#caffe_bvlc_0_1
parameters:
deploy_model: "blobs/deploy.prototxt"
weights: "blobs/model.caffemodel"
The type parameter specifies the network format used by the model. The following models are currently supported:
Caffe SSD (id:
com_bonseyes/network_formats#caffe_ssd_0_1)Caffe Bonseyes (id:
com_bonseyes/network_formats#caffe_bonseyes_0_1)NVIDIA-Caffe (id:
com_bonseyes/network_formats#caffe_nvidia_0_1)BVLC Caffe (id:
com_bonseyes/network_formats#caffe_bvlc_0_1)ONNX (id:
com_bonseyes/network_formats#onnx_0_1)
The parameters section specifies the model’s file path under the blobs’ folder. For the caffe based models the following parameters are required:
deploy_model: path to the caffe prototxt relative to the blobs’ directory containing the model YAML file.weights: path to the caffe weights relative to the blobs’ directory containing the model YAML file.
For the ONNX models the following parameters are required:
deploy_model: path to the ONNX file relative to the blobs’ directory containing the model YAML file.
A template of the model YML file is available in the AI Asset Container Generator.
An example model YML file is also available in the 3D Face Landmarks AI Asset.
algorithm.yml¶
The algorithm.yml is the highest-level configuration YAML file that specifies the components and the algorithms that are executed inside an AI App to solve a given AI challenge. An algorithm defines the relationship between the component’s input and output. Thus, the algorithm.yml file defines all the component’s parameters that are required to execute such algorithms. The schema of the file is described below:
Algorithm Configuration¶
All information that is necessary to uniquely define the functional behaviour of an algorithm |
|||
type |
object |
||
properties |
|||
|
|||
|
ID of the challenge that specifies this model |
||
type |
string |
||
|
name of the algorithm |
||
type |
string |
||
|
Parameters specific to the algorithm type, the schema depends on the type of algorithm chosen |
||
type |
object |
||
|
Algorithm configuration for the algorithm subcomponents |
||
type |
object |
||
additionalProperties |
type |
object |
|
properties |
|||
|
Name of the algorithm used to implement the subcomponent |
||
|
Parameters of the algorithm |
||
|
Algorithm configuration for the subcomponents of the subcomponent |
||
#/properties/subcomponents |
|||
|
Data used to test that an AI app implementing this specification is behaving correctly |
||
type |
object |
||
properties |
|||
|
Path to a file with the AI app inputs. The format depends on the AI app the algorithm implements and its configuration |
||
type |
string |
||
|
Path to a file with the AI app outputs that are expected when the inputs are injected in the AI app. The format depends on the AI app the algorithm implements and its configuration |
||
type |
string |
||
additionalProperties |
False |
||
|
Additional data used to test the algorithm component such as intermediate outputs. The schema depends on the algorithm type |
||
type |
object |
||
additionalProperties |
False |
||
A minimal algorithm configuration looks as follows:
algorithm: com_bonseyes/ai_algorithms#image_classification_preprocess_infer
challenge: com_bonseyes/challenges/mychallenge#challenge.yml
parameters: ...
subcomponents:
preprocessing:
parameters: ...
inference:
parameters:
model: model.yml
...
A template of the algorithm YML file is available in the AI Asset Container Generator.
The algorithm field is used to select the AI App’s algorithm type. The following AI App’s algorithms are currently supported in LPDNN:
Image Classification using a Neutral Network with image pre-processing (id:
com_bonseyes/ai_algorithms#image_classification_preprocess_infer): this algorithm converts an image to a specific format and size, normalizes the pixel values and then executes a neutral network to compute the confidence of each possible image class. This algorithm solves AI challenges with interfacecom_bonseyes/interfaces#image_classification.Face Recognition using a Neutral Network with image pre-processing (id:
com_bonseyes/ai_algorithms#face_recognition_preprocess_infer): this algorithm converts a face image to a specific format and size, normalizes the pixel values and then executes a neutral network to compute the fingerprint for the face. This algorithm solves AI challenges with interfacecom_bonseyes/interfaces#face_recognition.Object detection using a Neutral Network with image pre-processing (id:
com_bonseyes/ai_algorithms#object_detection_preprocess_infer): this algorithm converts an image to a specific format and size, normalizes the pixel values and then executes a neutral network to compute bounding boxes, landmarks and confidence of the detected objects classes. This algorithm solves AI challenges with interfacecom_bonseyes/interfaces#object_detection.Image segmentation using a Neutral Network with image pre-processing (id:
com_bonseyes/ai_algorithms#image_segmentation_preprocess_infer): this algorithm converts an image to a specific format and size, normalizes the pixel values and then executes a neutral network to compute a segmentation mask and confidence of the detected objects classes. This algorithm solves AI challenges with interfacecom_bonseyes/interfaces#image_segmentation.Audio Classification using a Neutral Network with audio pre-processing (id:
com_bonseyes/ai_algorithms#audio_classification_preprocess_infer): this algorithm converts an audio snippet to a specific format and then executes a neutral network to compute the confidence of each possible audio snippet class. This algorithm solves AI challenges with interfacecom_bonseyes/interfaces#audio_classification.Signal Classification using a Neutral Network with signal pre-processing (id:
com_bonseyes/ai_algorithms#signal_classification_preprocess_infer): this algorithm converts a signal stream to a specific format and then executes a neutral network to compute the confidence of each possible signal class. This algorithm solves AI challenges with interfacecom_bonseyes/interfaces#signal_classification.
The challenge field points to the AI challenge YAML file that describes the challenge being answered by the algorithm configuration. The file may refer the AI Challenge YAML file with a relative name if it is contained in the same package or use the syntax package_name#path/to/challenge.yml to refer to a challenge in another package.
The parameters field contains the parameters that define the behaviour of the algorithm. The parameters depend on the algorithm.
The subcompenents field provides parameters and specifications for the subcomponents of the algorithm, e.g., pre-processing, inference.
Subcomponents¶
In this sub-section we describe the parameters and details of the subcomponents. LPDNN’s AI Apps have two main components:
Pre-processing: Section that specifies how the input must be prepared.
Inference: Section that specifies which neutral network model should be executed.
Pre-processing¶
The pre-processing is the first subcomponent of an LPDNN’s AI App. The pre-processor takes the raw input and transform it into the format and specifications that the neural network expects. The pre-processor can execute several functions such as cropping, normalization, filtering, domain transformations, etc. Each function needs to be specified in the subcomponents.inference.parameters field.
Image Pre-processor
The image pre-processor has the following format:
metadata:
title: Image preprocessor
parameters: parameters.yml
interface: com_bonseyes/interfaces#image_preprocessing
The pre-processor supports the following configuration parameters in the algorithm.yml:
Parameters for image pre-processing¶
Parmameters used to perfom image pre-processing |
||||||
type |
object |
|||||
properties |
||||||
|
Size of the input to the model |
|||||
type |
object |
|||||
properties |
||||||
|
type |
integer |
||||
|
type |
integer |
||||
|
Image format of the input to the model |
|||||
type |
string |
|||||
enum |
grayscale, bgr, rgb, rgbs |
|||||
|
Type of normalization filter used |
|||||
type |
string |
|||||
enum |
none, histogram_equalization_gray, histogram_equalization_rgb, tan_triggs |
|||||
|
Type of mean used for normalization |
|||||
type |
string |
|||||
enum |
constant, per-pixel, none |
|||||
|
File containing the per-pixel mean normalization data |
|||||
type |
string |
|||||
|
File containing the per-pixel std-dev normalization data |
|||||
type |
string |
|||||
|
filename where to dump normalized tile |
|||||
type |
string |
|||||
|
Array with per-channel mean normalization constant, the order of channels is given by the colormode |
|||||
type |
array |
|||||
items |
type |
number |
||||
|
Array with per-channel std-dev normalization constant, the order of channels is given by the colormode |
|||||
type |
array |
|||||
items |
type |
number |
||||
|
Cropping options |
|||||
type |
object |
|||||
properties |
||||||
|
Select: - fill: stretch the ROI content to fit inside the output tile [default] - fit: resize ROI content (while keeping its original aspect ratio) so that its longest side matches the corresponding output tile size - zoom: resize ROI content (while keeping its original aspect ratio) so that its shortest side matches the corresponding output tile size - center: set ROI to be the largest inscribed centered rectangle |
|||||
type |
string |
|||||
enum |
fill, fit, zoom, center |
|||||
|
Add a margin to the ROI as a proportion of the output width, resp. height |
|||||
type |
number |
|||||
|
filename where to dump cropped tile |
|||||
type |
string |
|||||
|
Parmameters used align the image based on landmarks |
|||||
type |
object |
|||||
properties |
||||||
|
Transform the image to match the input landmarks to the given landmarks positions. Default is no alignment. |
|||||
type |
string |
|||||
enum |
none, affine2, affine3, affine5_rigid, affine5_umeyama |
|||||
|
filename where to dump aligned tile |
|||||
type |
string |
|||||
|
Landmarks target positions |
|||||
type |
object |
|||||
properties |
||||||
|
landmark type id |
|||||
type |
string |
|||||
|
Landmark points. Landmarks coordinates are given on a scale of 1000000x1000000 which is rescaled relative to the dimension of the output tile. |
|||||
type |
array |
|||||
items |
type |
object |
||||
properties |
||||||
|
type |
integer |
||||
|
type |
integer |
||||
additionalProperties |
False |
|||||
The pre-processor assumes a single image as an input, e.g., rgb, grayscale. The output_size field should be specified for ONNX models, which assumes a NCHW layout, e.g., [1, 3, 120, 120] for rgb image.
An minimal image pre-processing configuration look like following:
color_mode: grayscale
normalization: constant
mean_data: [ 0 ]
std_data: [ 255 ]
output_size:
y: 120
x: 120
The first parameter color_mode describes the type of output image that should be generated by the pre-processing, it can be grayscale for grayscale image, bgr for BGR 8-bit images and rgb for RGB 8-bit images.
The normalization parameter specifies the type of normalization that should be applied to image. The options are the following: constant where a normalization constant is used to normalize each channel and per-pixel, where each point of the image is normalized with different parameters.
In the case of constant normalization the constants for mean and standard deviation are specified in the mean_data and std_data fields. For instance to normalize an RGB image with mean 127 on each channel and standard deviation 127 the following configuration would be used:
normalization: constant
mean_data: [ 127, 127, 127 ]
std_data: [ 127, 127, 127 ]
The pre-processor works with raw image data on [0, 255] range. Therefore, if your AI model has been trained and normalized on [0, 1] range, the values to set for the mean and std in the algorithm.yml need to be those used during training multiplied by 255, so as to bring back the data on [0, 1] range.
The per-pixel normalization would look like this the configuration file would include the following:
normalization: per-pixel
mean_file: blobs/mean.bin
std_file: blobs/std.bin
The mean_file and std_file point to binary files containing the per-pixel data.
Audio Pre-processor
The audio pre-processor computes MFCC features from the audio sample. It has the following format:
metadata:
title: Audio preprocessor
parameters: parameters.yml
interface: com_bonseyes/interfaces#audio_preprocessing
The pre-processor supports the following configuration parameters in the algorithm.yml:
Parameters for audio pre-processing¶
Parameters used to perform audio pre-processing |
|||
type |
object |
||
properties |
|||
|
Size of the input to the model |
||
type |
object |
||
properties |
|||
|
type |
integer |
|
|
type |
integer |
|
|
Type of normalization filter used |
||
type |
string |
||
enum |
undefined, none, mfcc |
||
|
Number of Mel filters |
||
type |
integer |
||
|
Number of FFT filters |
||
type |
integer |
||
|
Cut frequencies |
||
type |
object |
||
properties |
|||
|
type |
integer |
|
|
type |
integer |
|
|
window length in ms |
||
type |
integer |
||
|
Hop length |
||
type |
integer |
||
|
Power in db. Otherwise in log |
||
type |
boolean |
||
|
Htk function. Otherwise stanley |
||
type |
boolean |
||
|
Inverted col and rows |
||
type |
boolean |
||
|
Mean normalization constant |
||
type |
number |
||
|
Std-dev normalization constant |
||
type |
number |
||
|
Normalization for Mel filterbank |
||
type |
string |
||
|
Clip values between 0 and 255 |
||
type |
boolean |
||
|
filename where to dump preprocessed tile |
||
type |
string |
||
additionalProperties |
False |
||
Signal Pre-processor
The signal pre-processor has the following format:
metadata:
title: Signal preprocessor
parameters: parameters.yml
interface: com_bonseyes/interfaces#signal_preprocessing
The pre-processor supports the following configuration parameters in the algorithm.yml:
Parameters for signal pre-processing¶
Parameters used to perform signal pre-processing |
|||
type |
object |
||
properties |
|||
|
Size of the input to the model |
||
type |
object |
||
properties |
|||
|
type |
integer |
|
|
type |
integer |
|
|
|||
|
filename where to dump preprocessed tile |
||
type |
string |
||
additionalProperties |
False |
||
Inference¶
Inferece is the second subcomponent of an LPDNN’s AI App. The Inference processor takes prepared input from the pre-processor and exucutes the forward pass of the neural network, i.e., inference. The configuration of this subcomponent in the algorithm YAML file specifies which neutral network model should be executed.
The inference subcomponent supports the following configuration parameters:
type |
object |
|||||
properties |
||||||
|
Path to the model file |
|||||
type |
string |
|||||
|
Should the output of this model be fed back to its input using values specified in out_layers and input_layers? |
|||||
type |
boolean |
|||||
|
Ordered list of name of input layers for this model |
|||||
type |
array |
|||||
items |
type |
string |
||||
|
Ordered list of name of output layers from the model that will be saved in the json output |
|||||
type |
array |
|||||
items |
type |
string |
||||
|
Output format of the network: - value_list: a 1D vector of values, for example confidences - ssd: SSD output structure - nanodet: Nanodet-based format for object detection - nanodetPlus: Nanodet-plus based format for object detection - xy_list: a 1D vector of points (x,y) - bb_landmarks: feature maps with confidences, bbs, landmarks - openpifpaf: openpifpaf output format - none: no actual output (useful for partial backbone networks) - ksdd2: defect detection output that contains classification confidence and coordinates of defective pixels - clipped: clip the output in case the prediction is above or below a threshold of the average of previously estimated values - cyclops2gaze: converts the cyclops gaze (pitch, yaw) in radians to a left and right eye gaze vector (left-pitch, left-yaw, right-pitch, right-yaw) in degree - landmarks_head_pose_tuple: a tuple (3d landmarks, headpose). 3d landmarks is a flatten vector of size batch_size x num_landmarks x 3. headpose is a flatten vector of size batch_size x 7 x 1. - 3dmm_params: a 1D vector of values containing the morphable model parameters (3DMM) |
|||||
type |
string |
|||||
enum |
value_list, ssd, none, openpifpaf, openpifpaf_0_8, openpifpaf_0_11, openpifpaf_0_12, openpifpaf_0_12_13, openpifpaf_0_12_13_wholebody, openpifpaf_0_13_3, openpifpaf_0_13_3_wholebody, openpifpaf_0_13_3_wholebody_59pts, tddfa_v2, xy_list, xy_list/eyes_nose_5, xy_list/eyes_nose_mouth_5, xy_list/face_68, bb_landmarks, bb_landmarks/eyes_nose_5, bb_landmarks/eyes_nose_mouth_5, bb_landmarks/eyes_nose_mouth_5/v2, bb_landmarks/eyes_nose_mouth_5/v3, nanodet, nanodetPlus, yolov4, fcn, ksdd2, clipped, cyclops2gaze, landmarks_head_pose_tuple, 3dmm_params |
|||||
|
Indicator of the input tile size in case of split Ai Apps |
|||||
type |
object |
|||||
properties |
||||||
|
type |
integer |
||||
|
type |
integer |
||||
|
postprocessing parameters |
|||||
type |
object |
|||||
properties |
||||||
|
Body pose postprocessing configuration |
|||||
type |
object |
|||||
properties |
||||||
|
Non-maxima supression enabled flag |
|||||
type |
boolean |
|||||
|
Indicate a custom decoder (not a subset and a subgraph of body pose) |
|||||
type |
boolean |
|||||
|
An NMS-related parameter |
|||||
type |
number |
|||||
|
An NMS-related parameter |
|||||
type |
number |
|||||
|
CIF stride |
|||||
type |
integer |
|||||
|
CIF floor |
|||||
type |
number |
|||||
|
CAF stride |
|||||
type |
integer |
|||||
|
CAF score threshold |
|||||
type |
number |
|||||
|
Keypoint threshold (absolute) |
|||||
type |
number |
|||||
|
Keypoint threshold (relative) |
|||||
type |
number |
|||||
|
Keypoint names |
|||||
type |
array |
|||||
items |
type |
string |
||||
|
Skeleton definition |
|||||
type |
array |
|||||
items |
type |
array |
||||
items |
type |
number |
||||
|
Weights definition |
|||||
type |
array |
|||||
items |
type |
number |
||||
additionalProperties |
False |
|||||
Usually, only two parameter are used:
The
subcomponents.inference.parameters.modelis set to the path of the model YAML file model.yml.The
subcomponents.inference.parameters.out_formatis set to specify the post-processing type (if any) that should be executed after the forward pass of the neural network.
Algorithm Configuration Examples¶
In this sub-section, we show examples of pre-defined algorithms:
Image Classification using a Neutral Network with image pre-processing¶
The specification of this algorithm and their subcomponents is give here: Image Classification Preprocess Infer Algorithm.
A minimal algorithm.yml configuration file for this algorithm is the following:
algorithm: com_bonseyes/ai_algorithms#image_classification_preprocess_infer
subcomponents:
preprocessing:
parameters:
color_mode: grayscale
normalization: constant
mean_data: [ 0 ]
std_data: [ 255 ]
output_size:
y: 120
x: 120
inference:
parameters:
model: model.yml
challenge: com_bonseyes/challenges/mychallenge#challenge.yml
Face Recognition using a Neutral Network with image pre-processing¶
The specification of this algorithm and their subcomponents is give here: Image Classification Preprocess Infer Algorithm.
A minimal algorithm.yml configuration file for this algorithm is the following:
algorithm: com_bonseyes/ai_algorithms#face_recognition_preprocess_infer
parameters:
flip: true
subcomponents:
preprocessing:
color_mode: grayscale
normalization: constant
mean_data: [ 0 ]
std_data: [ 255 ]
output_size:
y: 120
x: 120
inference:
model: model.yml
challenge: com_bonseyes/challenges/mychallenge#challenge.yml
The flip parameter decides whether the face fingerprint returned by the module is fingerprint of the image or the
fingerprint of the image concatenated with the fingerprint of the mirrored image.
Object detection using a Neutral Network with image pre-processing¶
The specification of this algorithm and their subcomponents is give here: Object Detection Preprocess Infer Algorithm.
A minimal algorithm.yml configuration file for this algorithm is the following:
algorithm: com_bonseyes/ai_algorithms#object_detection_preprocess_infer
subcomponents:
preprocessing:
parameters:
color_mode: grayscale
normalization: constant
mean_data: [ 0 ]
std_data: [ 255 ]
output_size:
y: 120
x: 120
inference:
parameters:
model: model.yml
out_format: Post_Processing_Format
challenge: com_bonseyes/challenges/mychallenge#challenge.yml
Object detection AI Apps usually involve a post-processing step after inferece to decode the detected object’s istances. The inference.parameters.out_format field defines the format of such post-processing.
Image segmentation using a Neutral Network with image pre-processing¶
The specification of this algorithm and their subcomponents is give here: Image Segmentation Preprocess Infer Algorithm.
A minimal algorithm.yml configuration file for this algorithm is the following:
algorithm: com_bonseyes/ai_algorithms#image_segmentation_preprocess_infer
subcomponents:
preprocessing:
parameters:
color_mode: grayscale
normalization: constant
mean_data: [ 0 ]
std_data: [ 255 ]
output_size:
y: 120
x: 120
inference:
parameters:
model: model.yml
out_format: Post_Processing_Format
challenge: com_bonseyes/challenges/mychallenge#challenge.yml
Image segmentation AI Apps usually involve a post-processing step after inferece to apply the segmentation mask. The inference.parameters.out_format field defines the format of such post-processing.
Audio Classification using a Neutral Network with audio pre-processing¶
The specification of this algorithm and their subcomponents is give here: Audio Classification Preprocess Infer Algorithm.
An algorithm.yml configuration file for this algorithm is the following:
algorithm: com_bonseyes/ai_algorithms#audio_classification_preprocess_infer
subcomponents:
preprocessing:
parameters:
dump_tile: audio_dump.json
filter: mfcc
output_size:
y: 40
x: 32
numMels: 128
numFFT: 2048
freq:
low: 0
high: 8000
winLength: 2048
frameShift: 512
db: true
htk: false
inverted: false
clipINT8: false
mean_data: 0
std_data: 1
melNorm: None
inference:
parameters:
model: model.yml
challenge: com_bonseyes/challenges/mychallenge#challenge.yml
Signal Classification using a Neutral Network with signal pre-processing¶
The specification of this algorithm and their subcomponents is give here: algorithms/signal_classification_preprocess_infer.
A mininal algorithm.yml configuration file for this algorithm is the following:
algorithm: com_bonseyes/ai_algorithms#signal_classification_preprocess_infer
subcomponents:
inference:
parameters:
model: model.yml
preprocessing:
parameters:
dump_tile: signal_dump.json
output_size:
x: 1
y: 256
challenge: com_bonseyes/challenges/mychallenge#challenge.yml
An example algotithm YML file is also available in the 3D Face Landmarks AI Asset.
Deployment¶
The deployment folder contains deployment.yml files with the AI App’s deployment configuration. A deployment configuration YAML file specifies certain parameters for an algorithm implementation, e.g., what inference engine to use for the executation of the neural network, the data type (FP32, FP16, INT8) or the backends to use per layer. Several deployment.yml files can be stored under deployment/ for different configurations.
The schema of the supported deployment configurations are described below:
Algorithm Deployment specification¶
All information required by the deployment tool to generate a AI app from an algorithm specification. |
||||
type |
object |
|||
properties |
||||
|
||||
|
The name of the component to use |
|||
type |
string |
|||
|
Name of the generate AI-app |
|||
type |
string |
|||
|
Aiapp version as major.minor.maintenance.build |
|||
type |
string |
|||
|
Metadata for the deployed AI-app |
|||
|
Parameters required by the tool to deploy the algorithm |
|||
type |
object |
|||
|
type |
object |
||
additionalProperties |
type |
object |
||
properties |
||||
|
Component to use to implement the role |
|||
type |
string |
|||
|
Parameters for the component |
|||
type |
object |
|||
|
Deployment configuration for sub-components |
|||
#/properties/subcomponents |
||||
additionalProperties |
False |
|||
A minimal deployment.yml file looks like:
ai_app_name: "MY-APPLICATION"
ai_app_version: "v0.1"
ai_app_metadata:
title: Image classification
author:
email: hello@bonseyes.com
name: Bonseyes Community Association
description: |
This AI app analyzes an image and returns the probability that the image belongs to any given class.
extra:
- id: com_bonseyes/marketplace/metadata#tags
value:
- bonseyes
- image
- computer vision
- cnn
- lpdnn
license: Bonseyes Consortium License
component: com_bonseyes/lpdnn#core/components/image_classification_preprocess_infer
subcomponents:
inference:
component: com_bonseyes/lpdnn#engines/lne/components/network_processor
parameters:
optimizations: [all]
data_type: F32
The main subcomponent in the deployment YAML file is the inference subcomponent, which defines the network_processor to use, i.e., inference engine to execute the neural network, in the component type field and the characteristic in the parameters field. Next, we specify each of the possible components that can be used for inference.
Deployment engines¶
As explained in LDPNN’s Inference engines, LPDNN supports the following network processors (inference engines), each of these allowing different configurations:
LNE¶
#/definitions/model_deployment |
|||
definitions |
|||
|
Deployment models for the LPDDN inference engine |
||
< All information used necessary to configure the LPDNN engine to execute a given model. |
|||
type |
object |
||
properties |
|||
|
Data type used for computations |
||
type |
string |
||
enum |
ANY, F32, F16, S16, S8, U8 |
||
default |
F32 |
||
|
Optimizations to enable |
||
type |
array |
||
|
File containing qdata |
||
type |
string |
||
|
Generation configuration for each layer |
||
type |
object |
||
default |
|||
additionalProperties |
False |
||
TensorRT¶
#/definitions/model_deployment |
||||
definitions |
||||
|
Deployment models for the LPDDN inference engine |
|||
< All information used necessary to configure the LPDNN engine to execute a given model. |
||||
type |
object |
|||
properties |
||||
|
Data type used for computations |
|||
type |
string |
|||
enum |
ANY, F32, F16, S16, S8, U8 |
|||
default |
F32 |
|||
|
Optimizations to enable |
|||
type |
array |
|||
|
File containing qdata |
|||
type |
string |
|||
|
File containing list of calibration tiles |
|||
type |
string |
|||
|
Generation configuration for each layer |
|||
type |
object |
|||
default |
||||
|
Name of the tensor rt engine file |
|||
type |
string |
|||
|
DLA used on device |
|||
type |
integer |
|||
|
Force engine rebuild on every run |
|||
type |
boolean |
|||
|
Use quantisation calibrator |
|||
type |
boolean |
|||
|
Calibration batch size |
|||
type |
integer |
|||
|
Number of calibration batches |
|||
type |
integer |
|||
|
Optimisation profiles for tensor rt engine build |
|||
type |
object |
|||
properties |
||||
|
Optimal tensor shape |
|||
type |
array |
|||
|
Minimal tensor shape |
|||
type |
array |
|||
|
Maximal tensor shape |
|||
type |
array |
|||
|
Execution shape for batch execution |
|||
type |
array |
|||
additionalProperties |
False |
|||
NCNN¶
#/definitions/model_deployment |
|||
definitions |
|||
|
Deployment models for the LPDDN inference engine |
||
< All information used necessary to configure the LPDNN engine to execute a given model. |
|||
type |
object |
||
properties |
|||
|
Data type used for computations |
||
type |
string |
||
enum |
ANY, F32, F16, S16, S8, U8 |
||
default |
F32 |
||
|
Optimizations to enable |
||
type |
array |
||
|
File containing qdata |
||
type |
string |
||
|
Generation configuration for each layer |
||
type |
object |
||
default |
|||
additionalProperties |
False |
||
ONNXruntime¶
#/definitions/model_deployment |
|||||
definitions |
|||||
|
Deployment models for the LPDDN inference engine |
||||
< All information used necessary to configure the LPDNN engine to execute a given model. |
|||||
type |
object |
||||
properties |
|||||
|
Data type used for computations |
||||
type |
string |
||||
enum |
ANY, F32, F16, INT64, S16, S8, U8 |
||||
default |
F32 |
||||
|
Optimizations to enable |
||||
type |
array |
||||
|
File containing qdata |
||||
type |
string |
||||
|
Define the logging level |
||||
type |
string |
||||
enum |
verbose, info, warning, error, fatal |
||||
|
Defines verbosity level when logging severity is verbose; A higher value is more verbose. |
||||
type |
integer |
||||
|
Choose between sequential or parallel execution |
||||
type |
string |
||||
enum |
sequential, parallel |
||||
|
Enable the ORT engine profiling and provide the profile file path prefix |
||||
type |
string |
||||
|
ONNX graph optimization level |
||||
type |
string |
||||
enum |
none, basic, extended, all |
||||
|
The path to save the optimized model |
||||
type |
string |
||||
|
Sets the max number of inter-op threads used to parallelize the execution |
||||
type |
integer |
||||
|
Sets the max number of intra-op threads used to parallelize the execution (no OpenMP builds) |
||||
type |
integer |
||||
|
Defines available execution providers |
||||
type |
object |
||||
default |
|||||
properties |
|||||
|
CUDA execution provider configuration. |
||||
type |
object |
||||
properties |
|||||
|
CUDA device id |
||||
type |
integer |
||||
default |
0 |
||||
|
The size limit of the device memory arena in bytes |
||||
type |
integer |
||||
|
The type of search done for cuDNN convolution algorithms |
||||
type |
string |
||||
enum |
exhaustive, heuristic, default |
||||
|
Whether to do copies in the default stream or use separate streams |
||||
type |
boolean |
||||
default |
True |
||||
|
Check tuning performance for convolution heavy models |
||||
type |
integer |
||||
default |
0 |
||||
|
TensorRT execution provider configuration. |
||||
type |
object |
||||
properties |
|||||
|
CUDA device id |
||||
type |
integer |
||||
default |
0 |
||||
|
Max workspace memory size for engine build |
||||
type |
integer |
||||
|
Max number of partition iterations |
||||
type |
integer |
||||
|
Min subgraph size |
||||
type |
integer |
||||
|
Enable FP16 |
||||
type |
boolean |
||||
default |
True |
||||
|
Enable Int8 |
||||
type |
boolean |
||||
default |
False |
||||
|
Path to the Int8 calibration table |
||||
type |
string |
||||
|
Enable DLA |
||||
type |
boolean |
||||
default |
False |
||||
|
Select DLA core |
||||
type |
integer |
||||
|
Enable engine cache |
||||
type |
boolean |
||||
|
Path to the engine cache |
||||
type |
string |
||||
|
Enable subgraphs dump |
||||
type |
boolean |
||||
additionalProperties |
False |
||||
A template of the deployment YML file is available in the AI Asset Container Generator.
An example deployment YML file is also available in the 3D Face Landmarks AI Asset.
Deployment packages¶
As explained in LDPNN’s Deployment of AI applications on embedded devices, an LPDNN Deployment Package is a collection of tools, executables, libraries, inference engines and backends that allows the actual execution of the LPDNN AI application. The collection of libraries and binaries that are copied on the target platform for the execution of the DNN is called a runtime. The runtime dinamically loads an AI application and executes it based on its defined configuration. LPDNN’s deployment packages are platform-specific as they contain the inferences engines and backends supported by the HW platform.
Deployment packages, including LPDNN runtimes, can be obtained by asking access to one of the BonsAPPS’s partner. LPDNN’s deployment packages can be found here.
A template of where the deployment packages should be placed is available in the AI Asset Container Generator.
An example containing deployment packages is also available in the 3D Face Landmarks AI Asset. The script get_packages.sh allows the user to donwload deployment packages by executing:
bash get_packages.sh ${platformName} # For instance bash get_packages.sh jetson_nano-jetpack4.6
Generate an AI App¶
Prerequisites¶
This section assumes:
All the steps in the create an LPDNN’s file tree section have been completed.
The local environment has been set up as explained in Prerequisites
Generation¶
There are two methods to generate an AI App:
AI App generator script: Python script that produces an AI App.
Bonseyes CLI: Main command line interface tool for Bonseyes tools and workflows.
AI App generator script¶
To use this script the following steps need to be performed:
Change directory to the LPDNN’s directory, e.g., LPDNN root directory in AI Asset.
Create a build folder:
mkdir buildExecute the following command:
deployment_packages/${platformName}/tools/ai_app_generator/bin/ai-app-generator \ --algorithm-file catalog/${modelName-version-size-precision}/algorithm.yml \ --challenge-file challenge/${challengeName}/challenge.yml \ --deployment-file deployment/${modelName-version-size-precision}/deployment.yml \ --output-dir build/${new-aiapp-name}
For instance, to generate an AI App for the model mobilenet-v2-224x224-fp32 (imagenet challenge) on raspberry4b_64-ubuntu20:
deployment_packages/raspberry4b_64-ubuntu20/tools/ai_app_generator/bin/ai-app-generator \ --algorithm-file catalog/mobilenet-v2-224x224-fp32/algorithm.yml \ --challenge-file challenge/imagenet/challenge.yml \ --deployment-file deployment/mobilenet-v2-224x224-fp32/deployment.yml \ --output-dir build/mobilenet-v2-224x224-fp32
After executing the command a new LPDNN AI App will be present in the build folder with the given name. A number of file will be included in the AI App folder among which the most important ones are described at LPDNN AI application (AI App).
To regenerate the AI App with the same name, the flag --force can be used. Beware as this flag will first erase the previous AI App to then compile a new one.
Bonseyes CLI¶
It is also possible to build AI Apps with the Bonseyes CLI tool. To do so, this generation option includes an extra prerequite step:
Download and build the sources of the target platform’s DPE as explained in the platform’s Description in the user guide.
Have the ${platformName_source} and ${platformName_build} folders in lpdnn repository.
To generate an AI App with the Bonseyes CLI tool, execute the following commands:
Change directory to the LPDNN’s directory, e.g., LPDNN root directory in AI Asset.
Copy you target platform’s sources and build directories to LPDNN root directory:
cp /Path/to/{platformName}_source /Path/to/{platformName}_build .
Create a build folder:
mkdir buildExecute the following command:
bonseyes --packages-dir . ai-app generate \ --algorithm-config catalog/${modelName-version-size-precision}/algorithm.yml \ --challenge challenge/${challengeName}/challenge.yml \ --deployment-config deployment/${modelName-version-size-precision}/deployment.yml \ --deployment-tool deployment_packages/${platformName}/deployment_tool.yml build/${new-aiapp-name}
For instance, to generate an AI App for the model mobilenet-v2-224x224-fp32 (imagenet challenge) on raspberry4b_64-ubuntu20:
bonseyes --packages-dir . ai-app generate \ --algorithm-config catalog/mobilenet-v2-224x224-fp32/algorithm.yml \ --challenge challenge/imagenet/challenge.yml \ --deployment-config deployment/mobilenet-v2-224x224-fp32/deployment.yml \ --deployment-tool deployment_packages/raspberry4b_64-ubuntu20/deployment_tool.yml \ build/mobilenet-v2-224x224-fp32
After executing the command a new LPDNN AI App will be present in the build folder with the given name. A number of file will be included in the AI App folder among which the most important ones are described at LPDNN AI application (AI App).
Development¶
If the generation of an LPDNN AI App is not possible due to not supported features such as:
Not supported operator by the targeted inference engine
Please, you may try generate the AI App with another inference engine for your target device.
If the generation of an LPDNN AI App is not possible due to not supported features such as:
Specific pre-processing / post-processing not existing.
Not supported operator by the target inference engine (LNE only).
AI Class not existing, e.g., signal regression.
Please, follow the dev guidelines for LPDNN’s Description to get started with LPDNN development in LPDNN’s SDK.
Execute an AI App on host device¶
Execution of FP32 AI Apps¶
As explained in LDPNN’s Deployment of AI applications on embedded devices, two elements are need to execute an AI Application on a device:
An LPDNN AI application: Created in previous steps.
An LPDNN Deployment Package: Donwloaded in previous steps.
To execute an FP32 AI Apps on your host, you can use the aiapp-cli (standalone executable) that allows to easily execute an aiapp from the command line. It receives as input parameters the aiapp configuration file and the input file(s) to be processed. It will internally instantiate the correct aiapp class according to the specified configuration file and generate human-readable result. To execute the AI App, follow the next steps:
The executable is available under bin/. Change directory to the deployment package binaries that match you current device:
cd deployment_packages/${platformName}/bin # For instance: cd deployment_packages/x86_64-ubuntu20_cuda/bin
Set the library’s and python’s path:
source set-lib-path.sh
Infer an AI App on an input sample:
./aiapp-cli --cfg ../../../build/${new-aiapp-name}/ai_app_config.json -f /Path/To/Input/File{.png/.wav/.json} # For instance: ./aiapp-cli --cfg ../../../build/mobilenet-v2-224x224-fp32-cli/ai_app_config.json -f /Path/To/Input/File{.png/.wav/.json}
An example of a python-based AI APP cli (aiapp-cli.py) with the same execution parameters is also available in all LPDNN’s deployment_package under the bin/ folder.
Processing options¶
Input format¶
The input file can be a .jpg/png format for image-based AI Apps or .wav for audio files. However, it is also possible to pass an input tile in JSON format that may contain any kind of data. The JSON file must have the following structute:
{ "data":[1.5883,0.272,0.89910,...,...], # Modify based on Input "dim":[1,3,224,224], # Modify based on AI App "info":"NCHW" # Currently only NCHW input layout is supported }
JSON input tiles are not pre-processed by LPDNN, i.e., pre-processing step is skipped, as they usually they serve to concatenate several AI App by feeding the results of the fist one into the input of the second one. Note: Currently only supported input layout is NCHW
Split pre-proceesing and inference¶
If the file provided in input to an AI App has .json suffix, it is considered as a tile, so no preprocessing is done and the data are sent directly to inference.
The --out-tile option allows to generate the tile (that is the output of the preprocessor) in a JSON file as an AI App blob, that is, a flattened data array of floats plus a dim array representing the actual dimensions. This makes it easy to perform preprocessing and inference in two separate stages if needed.
Additional input¶
Extra input¶
An given AI App may require additional information, e.g., region-of-interest or landmarks, as an input. This information can be provided in input to aiapp-cli by sending the extra input as stdin:
cat landmarks.json | ./aiapp-cli --cfg ../../../build/${new-aiapp-name}/ai_app_config.json -f /Path/To/Input/File
To generate a file such as landmarks.json from a first AI App, you may execute it with the --out-inference parameter to obtain a JSON file with the results:
./aiapp-cli --cfg ../../../build/${new-aiapp-name}/ai_app_config.json -f /Path/To/Input/File --out-inference landmarks.json
Multiple inputs¶
Some AI Apps, however, require multiple inputs, some of which are fed directly from the output of the same AI App (temporal networks).
If a model supports multiple inputs, e.g., tsm-optimized for gesture-recognition, you can use the --additional-inputs <file.json> argument to specify a JSON file that contains the additional values.
Values in the JSON must use the same format of the file produced by --out-inference. Input order is defined in the algorithm.yml of the model, using the inference/parameter/input_layers field.
When creating manually a JSON file to pass addtional inputs, an empty “blob” must be added at the beginning of the array. For example if you have 2 additional inputs, the JSON array should contains this: [empty blob, <additional_input1>, <additional_input2>]
This is done because the output of --out-inference includes both default output and additional outputs ([default, additional1, additional2, …]) and by doing it this way, it is possible to directly feed the produced JSON back to the model without having to change it, which is useful for some models.
Note that if a model has multiple output (also specified in the algorithm.yml file, they can be retrieved in the file generated with --out-inference).
gesture_app=../share/ai-apps/tsm-optimized/ai_app_config.json # 1. Run the app without additional inputs the first time ./aiapp-cli --cfg $gesture_app -f $image --out-inference previous_output.json # 2. Run the app and pass previous output as additional input the second time ./aiapp-cli --cfg $gesture_app -f $image --additional-inputs previous_output.json
Concatenation of two AI App¶
Two AI Apps can be concatenated by redirecting the output of the first AI App into the second AI App.
Bash¶
Pre-built AI Apps can be concatenated through bash calls. The output logs of the first AI App are not displayed and the result is generated in json format, which is fed into the following AI App as stdin:
./aiapp-cli --cfg $face_detection_aiapp -f $image | ./item -i 0 | \ ./aiapp-cli --cfg $emotion_aiapp -f $image
Please, note the use of the ./item utility script in the commands above. Both face detection and landmark detection aiapps generate in output a list of items (one per face), where each item contains a bounding box and possibly landmarks. Emotion aiapp is instead able to process one face at a time, so it takes in stdin information regarding the bounding box and landmarks of a single face. We thus need a way to select which face to process. ./item -i 0 simply reads the output results of the first AI App and feed an item (by index) to second AI App..
If needed it is easy to provide different selector scripts with different behaviour, for example to select the biggest face, or the more central one, or the one with the highest confidence.
Python¶
AI Apps can also be concatenated in python to create a single more complex application as follows:
# Read file with open(sample_file, 'rb') as fp: binary_data = fp.read() # Create image sample = aiapp.encoded_sample(binary_data) # Execute Face Detection AI App res = aiapp.execute(sample, {}) for item in res.items: # Set ROI and landmarks to input image sample.roi = item.bounding_box sample.landmarks = item.landmarks # Execute Emotion AI App res = aiapp.execute(sample, {})
An example of AI APP cli (aiapp-cli.py) is available in all LPDNN’s deployment_package under the bin/ folder.
C++¶
During development, C++ code can also be concatenated to create a single built-in more complex application as follows:
# Read file auto image_content = app::read_binary_file(filename); # Create image auto image = ai_app::Image(ai_app::Image::Format::encoded, image_content, {}); # Execute Face Detection AI App auto results = aiapp_facedet->execute(image); for (auto item : result.items) { # Set ROI and landmarks to input image app::object_detection_item_to_image(item, image); # Execute Emotion AI App auto results = aiapp_emotion->execute(image); }
Other options¶
For more options about inferring an AI App, execute:
./aiapp-cli -h --cfg <file> Ai-app configuration file --info Show aiapp information -f <file;file..> Sample file(s) to process -d <dirname> Sample directory to process -p <file> Generate metrics file -l <filename> Generate layer dump file --out-tile <filename> Generate preprocessed tile in json format --preprocess-only Preprocessing only (skip inference) --out-inference <filename> Generate raw inference out in json format --additional-inputs <file> Path to JSON generated with --out-inference, provides values for additional model inputs (lpdnn/image detection only) -r <N> Repeat inference N times -rr <N> Repeat creation and inference N times --help Show this help
Quantisation workflow for LPDNN’s engines¶
LPDNN curently supports post-training quantization (PTQ) for its inference engines. To execute quantized models, some pre-steps need to be followed.
TensorRT¶
TensorRT supports FP16 and INT8 quantization.
FP16¶
For FP16 deployment, the following steps need to be performed:
Change the
subcomponent.inference.parameters.data_typefield to F16 in the deployment-file.yml.Note: Data type in LPDNN is F16, not FP16Generate again the target AI App using the new deployment YAML file.
Execute the AI App as explained in the previous section.
INT8¶
TensorRT provides it’s own calibration tool for INT8 deployment. To use the TensorRT quantization tool, perform the following steps:
Prepare a calibration dataset to adjust the DNN’s activations’ range by calculating the activation’ scale and offset in order to retain a high amount of accuracy during the quantization process.
We need to obtain pre-processed tiles to make sure the neural network’s calibration process ontains the real range that network sees during inferece.
To obtain the pre-processed tiles, have a FP32 ai-app generated following the steps explained in previous sections.
Run the preprocessing-only mode of the aiapp-cli executable for the AI App (compiled with any engine).
cd deployment_packages/${platformName}/bin source set-lib-path.sh ./aiapp-cli --cfg ../../../build/${aiapp-name}/ai_app_config.json --preprocess-only --out-tile <tile-n.json> -f <img-n.jpg>
Make sure to prepare enough representative tiles for the calibration set.
Make a text file, e.g., cfile.txt, containing the paths, line by line, toward the <tile-n.json> tiles generated in the previous step.
In the deployment-file.yml for tensorRT engine, add
qcalibrator,cfile,cbatch_size, andcbatchesfields to thesubcomponent.inference.parameters.Set qcalibrator to true, set cfile to the absolute path of the file containing the tile paths (without “”).
Set cbatch_size to the desired calibration batch size, e.g., 1.
Set cbatches to the number of calibration batches provided the data, e.g., if 100 tiles are available and a cbatch_size of 10 is chosen, there will be 10 cbatches.
Set data_type field to S8.
Generate again the target AI App using the new deployment YAML file.
Execute again the AI App. TensorRT will perform calibration process that might last some time. Some logs such as the following should appear:
[Trt::CreateEngine@73] Quantisation using TensorRT calibrator. .. Starting Calibration. Calibrated batch 0 in 0.0979145 seconds. Post Processing Calibration data in 1.12499 seconds. Calibration completed in 3.09242 seconds. Writing Calibration Cache for calibrator: TRT-7103-EntropyCalibration2
Upon a successful calibration, the platform-independent calibration results will be saved in qfile.txt in the AI App folder.
One can reuse the obtained results for the given AI App as a quantisation cache for building TensorRT engines on different target platforms without redoing the calibration process. To do so, add the path to the qfile.txt in deployment-file.yml’s
subcomponent.inference.parameters.qfilefield before generating the AI App. If so, cbatch_size, and cbatch_size fields can be removed from the deployment file.
ONNXruntime¶
ONNXruntme supports INT8 quantization.
INT8¶
LPDNN’s onnxruntime engine is able to execute quantized INT8 ONNX models directly. Hence, the only neeed steps are the following:
Quantize your model in the AI Asset as explained in onnxQuantize.
Make sure to have the quantized ONNX model in
catalog/${modelName-version-size-precision}/blobsand the right path to it on thecatalog/${modelName-version-size-precision}/model.yml.In the deployment-file.yml, set data_type field to S8 under
subcomponent.inference.parameters.Generate the AI App as explained in previous sections.
A quantized AI App is ready to be executed.
NCNN¶
NCNN supports FP16 and INT8 quantization.
FP16¶
For FP16 deployment, the following steps need to be performed:
Change the
subcomponent.inference.parameters.data_typefield to F16 in the deployment-file.yml.Note: Data type in LPDNN is F16, not FP16Generate again the target AI App using the new deployment YAML file.
Execute the AI App as explained in the previous section.
INT8¶
NCNN provides its own calibration tool to calculate the activation ranges against a valiadation dataset. LPDNN provides a pre-compiled ncnn2table script:
Have a pre-compiled FP32 model using NCNN engine as explained in previous sections.
Have a calibration dataset and generate a quantisation file as follows:
./deployment_packages/${platformName}/tools/ncnn/ncnn2table --param=build/${aiapp-name}/model.param --bin=build/${aiapp-name}/model.bin --images=PATH/TO/IMAGES_DIR --output=build/${aiapp-name}/quant.table --mean=0,0,0 # Modify --norm=1,1,1 # Modify --size=224,224 # Modify --thread=8
Include the path to the quantisation file: quant.table in deployment-file.yml’s
subcomponent.inference.parameters.qfilefield and set data_type field to S8.Generate again the target AI App, using the new deployment YAML file and a new name for the AI App (Avoid using –force as it will delete the quant.table).
Execute the AI App as explained in the previous section.
LNE¶
LNE supports INT8 quantization for both S8 and U8, symmetric and asymmetric types.
INT8¶
LPDNN provides a calibration tool to calculate the activations ranges against a validation dataset. To quantized a model with LNE, execute the following steps:
Execute the data extraction tool to dump the activations ranges against a validation dataset on a calibration.json file:
- python3 deployment_packages/${platformName}/tools/lib/lpdnn_onnx/extract_quantization_onnx.py
-m catalog/${modelName-version-size-precision}/blobs/${modelName-version-size-precision}.onnx –mean-pixel 0 0 0 # Modify –std-pixel 1 # Modify -i /Path/To/Calibration/Images/ –out-table build/${aiapp-name}/calibration.json
Include the path to the calibration JSON file in the deployment file in deployment-file.yml’s
subcomponent.inference.parameters.qfilefield.Choose the data type. LNE currently supports U8 data type for ARM CPU and S8 for Nvidia GPU.
Generate again the target AI App, using the new deployment YAML file and a new name for the AI App (Avoid using –force as it will delete the calibration.json).
Execute the AI App as explained in the previous section.
Deploy and benchmark an AI App on target device¶
For the deployment and benchmarking of an AI App on a target device, i.e., not the host where the AI App has been generated, the follwing step is required:
Setup the target hardware as explained in Setup platform section in the user guide and have a ${platformName_config}.
Bonseyes CLI benchmark¶
If automated benchmarking is desired, please refer to: Benchmark your AI-App you target HW section in the user guide to execute a benchmark with the Bonseyes CLI tool.
Custom deployment and benchmark¶
If custom deployment is desired, the AI App’s HTTP-worker interface can be used to deploy an AI App on a target device while posting samples, e.g., images, from your host PC. The http-worker can be found in all LPDNN’s deployment_packages under the bin/ folder and is started as follows:
./http-worker --cfg ../../../build/${new-aiapp-name}/ai_app_config.json -s ${IP_ADDR} -p ${Port}
Host side¶
Bash¶
It is then possible to connect to the worker from the host as follows (path to the image must contain the character “@” before the path):
curl --request POST --data-binary @/PATH/TO/FILE ${IP_ADDR}:${Port}/inference
It is also possible to generate execution metrics or specify additional parameters (such as bounding box or landmarks) by adding the corresponding fields to the header:
curl --request POST --data-binary @/PATH/TO/FILE --header 'x-metrics: all' --header "x-params: $(cat landmarks.json)" ${IP_ADDR}:${Port}/inference
Python¶
It is also possible to connect to the http-worker from a python interface:
url = 'http://' + '${IP_ADDR}' + ':' + '${Port}' + '/inference' headers = {'x-metrics': 'all'} headers = {'x-params': json.dumps({"bounding_box":{"origin":{"x":347,"y":113},"size":{"x":295,"y":405}}})} with open(input_sample, 'rb') as fp: with requests.post(url, data=fp.read(), headers=headers) as req: if req.status_code != 200: raise Exception('Error returned by the server worker') # parse the report report = req.json() req.close() print(report)
To change the type of input, e.g., rgb or input tile, the header should add the folliwing line:
# Input tile input headers = {'x-in-type': "tile-json"} # RGB input headers = {'x-in-type': "raw_rgb8"}
A complete python script, called http-client.py, for posting input samples to the http-worker is provided within each LPDNN’s deployment_package under the bin/ folder.
Upload AI App¶
THIS SECTIONS IS IN PROCESS
This guide assumes you already have the done the following:
Setup the local environment as explained in Prerequisites
Created an AI app with the procedure described in generate_ai_app
You have the deployment tool used to generate the AI app in the directory deployment_tool
Created a git repository on Gitlab that will host the AI app
Joined on the marketplace the challenge that the AI app is solving
Enrolled your gitlab user in the marketplace
To upload an AI app you need to do the following:
Create your author keys:
$ bonseyes license create-author-keys --output-dir author_keys
Package your ai-app for release with its dependencies and a redistribution licenses:
$ bonseyes --package deployment_tool/runtime marketplace package-ai-app \ --pull-images \ --ai-app ai_app \ --author-keys author_keys \ --amount "100 CHF" \ --recipients "test@dd.com,tost@dd.com" \ --regions https://www.wikidata.org/wiki/Q39,https://www.wikidata.org/wiki/Q40 \ --output-dir packaged_ai_appThe
--recipientsparameter can be used to restrict who can see the artifact on the marketplace, if omitted all users can see it.The
--regionsparameter can be used to restrict the regions in which the artifact can be seen, if omitted users of all regions can see it.Commit the packaged AI app in a gitlab repository that is accessible by the gitlab user you enabled in the marketplace
Upload the AI app to the marketplace:
$ bonseyes marketplace upload-ai-app --url $HTTP_URL_OF_GITLAB_REPO
The AI app will be added to your profile.
Create challenge-compliant interface for an AI App¶
LPDNN AI Apps might not be compliant with the specification of an AI Challenge published in the BMP. Therefore, a C++ interface needs to be use to parse the output results of the LPDNN AI App to the expected results specified in the AI Challenge. To do so, the following steps need to be followed:
Create LPDNN Challenge that includes the main LPDNN challenge files
Create a header file (.hpp) that includes the AI Challenge c++ interface and parses the AI App’s results
Create a CLI example that takes an built AI App and produces AI Challenge compliant results
Create LPDNN Challenge¶
Create a Gitlab repo for the challenge¶
Each challenge needs to have its own repository in GitLab in Challenges-LPDNN.
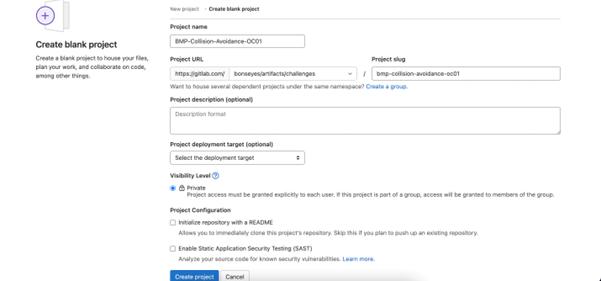
LPDNN full stack¶
Creation of a challenge repository in Gitlab
Naming Convention for Challenge Repository: The challenge repository name should follow a naming convention which is:
OrganizationAcronym-ChallengeName-ChallengeAcronym
where:
OrganizationAcronym: Organization to which the challenge belongs. For all BonsApps challenges, this acronym will be “BMP”
ChallengeName: Name of the challenge. If the challenge name has multiple words each word should start with a capital letter with a hyphen (“-“) in between the words.
ChallengeAcronym: This last part can be used as a distinguisher for challenges in case they belong to the same organization and have the same names (multiple challenges with the same name). In such cases this acronym serves as the challenge ID, e.g., OC1, OC2.
Add high-level challenge as a submodule¶
The high-level challenge needs to be added as a submodule so as to connect the high-level specifications with the low-level ones.
To add the high-level challenge as a submodule, execute a command such as:
$ git submodule add git@gitlab.com:bonseyes/artifacts/challenges/NameOfChallenge.git requirements
Add LPDNN challenge files¶
Follow BMP’s Creating the LPDNN challenge documentation to create the challenge.yml file that is needed for the creation of an AI App. In addition, files such as classes.txt or landmarks.txt might also be needed, depending on the Challenge AI class.
A readme file and some test samples should be also included in this repository, following this example.
Create header file¶
The objective of the header file is to parses the AI App’s results and make them compliant with the AI Challenge specifications. To do so, the c++ interface’s header file, from the requirements submodule, needs to be included.
A template for the header file, including the main methods, is available here. To complete the header file, the following steps are required:
Replace “LPDNN_AIAPP_CLASS” by the LDPNN AI class that the AI App is built upon, which is defined in the challenge.yml under ID (interface). For instance, image_classification or object_detection
Replace “CHALLENGENAME_Result” by the Challenge Interface header file name.
Add code your code to parse the AI App results into Result_Challenge(), challenge_interface() and to_json_str() methods. Any other method might also be modified or added if needed.
An example of a header file for 2D Bodypose Estimation is given here.
Create CLI example¶
A working CLI example in the LPDNN-Challenge needs to be created to showcase the AI App. To do so, follow next steps:
Create example folder in the LPDNN-Challenge folder, which contains include and test folders. A src folder might also be created.
Add the header file created in the previous step into the header folder.
Add main.cpp file into the test folder. A template of such a main.cpp file is available here. Modify CHALLENGENAME and Aiapp_NAME by the corresponding names that are used in the header file.
Add CmakeLists.txt file in the example folder. A template for a CmakeLists.txt file is available `here https://gitlab.com/bonseyes/bonsapps/1st-support-programme/qa/-/blob/main/templates/interface_c%2B%2B/CMakeLists.txt>`_. Replace AIAPPNAME-cli and aiapp_CHALLENGENAME by the corresponding names.
To build and run the CLI example, follow next steps:
Create build folder and change directory into it:
mkdir build cd build
Compile CLI example, giving the deployment package of the host machine:
cmake .. -DLPDNN_DEPLOYMENT_PACKAGE=/PATH/TO/{deployment_package} make
Run the CLI example:
./EXAMPLENAME-cli --cfg /PATH/TO/AIAPP//ai_app_config.json -f /PATH/TO/INPUT/SAMPLE