Definition¶
A Bonseyes AI application is the optimised representation of a DNN model to be efficiently executed on a target embedded device. AI applications are the ultimate result from the Bonseyes AI Assets to optimise the deployment of the trained model on the target device.
An AI application contains all the necessary elements or modules for the execution of a DNN:
Pre-processing: Step to prepare, normalize or convert the input data into the required input that is expected by the DNN.
DNN inference: Forward-pass of the neural network. The execution is taken care of by an inference engine.
Post-processing: Convertion of the neural network’s output into structured and human-readable information.
AI applications are produced by the Bonseyes inference framework: LPDNN.
LPDNN inference framework¶
LPDNN, which stands for Low-Power Deep Neural Network, is an enabling deployment framework that provides the tools and capabilities to generate portable and efficient implementations of DNNs. The main goal of LPDNN is to provide a set of AI applications for deep learning tasks, e.g., object detection, image classification, speech recognition, which can be deployed and optimised across heterogeneous platforms, e.g., CPU, GPU, FPGA, DSP, ASIC.

LPDNN AI classes¶
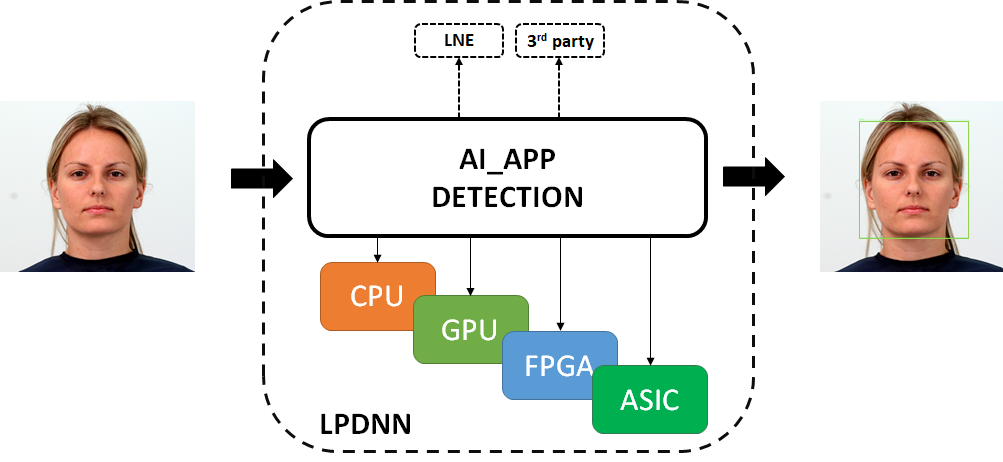
LPDNN overview¶
One of the main issues of deep learning systems is the hardship to replicate results across different systems. To solve this issue, LPDNN features a full development flow for deep learning solutions on embedded devices by providing platform support, sample models, optimisation tools, integration of external libraries and benchmarking. LPDNN’s full development flow makes the AI solution reliable and easy to replicate across systems.
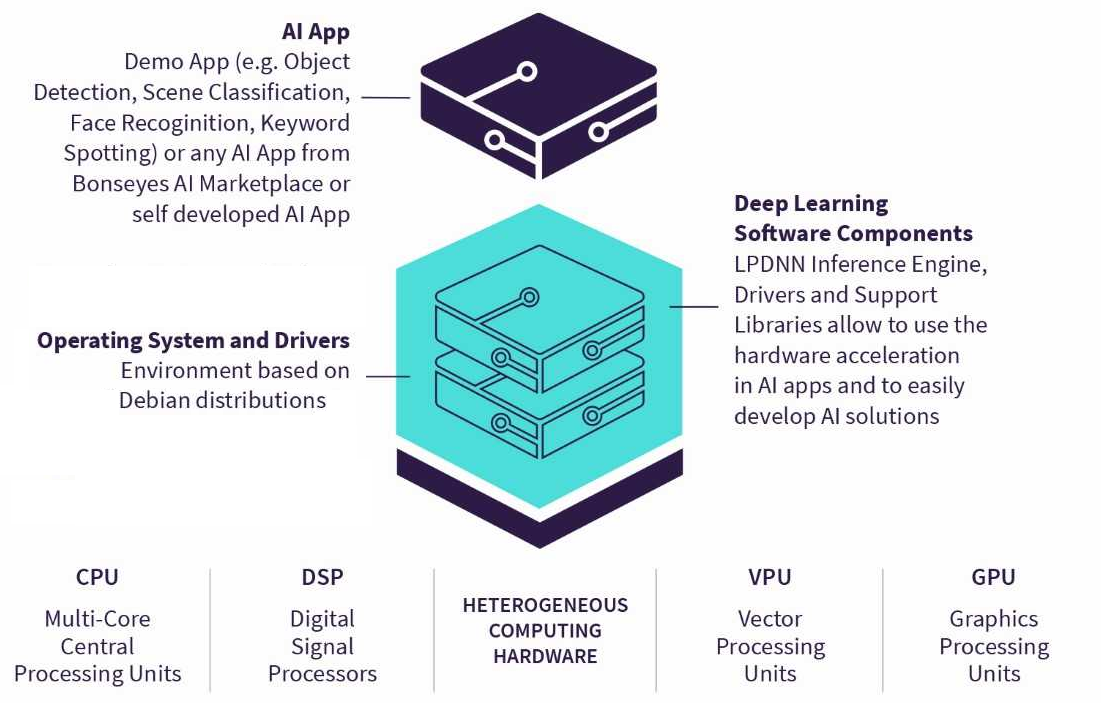
LPDNN full stack¶
Next, we introduce LPDNN’s architecture by further describing the concept of AI applications, LPDNN ‘s inference engines and the support for heterogeneous platforms.
Inference engines¶
AI applications contain a hierarchical but flexible architecture that allows new modules to be integrated within the LPDNN framework through an extendable and straightforward API. For instance, LPDNN supports the integration of 3rd-party self-contained inference engines to perform DNN inference. Currently, these are LPDNN’s supported inference engines:
LNE: LPDNN Native Engine (LNE) allows the execution of DNNs accross arm-based and x86 CPUs as well as on Nvidia-based GPUs.
NCNN: NCNN ports the execution of DNNs on GPU through the Vulkan driver.
TensorRT: TensorRT accelerates the DNN inference on Nvidia-based GPUs.
ONNXruntime: ONNXruntime enables the direct execution of ONNX models on CPUs and GPUs.
The inclusion of external engines also benefits LPDNN as certain embedded platforms provide their own specific and optimised framework to deploy DNNs on their hardware.
Heterogeneous computing support¶
One of the main factors for LPDNN’s adoption is performance portability across the wide span of hardware platforms. LPDNN’s flexible architecture allows the main core to remain small and dependency-free while additional 3rd party libraries or inference engines are only included when needed and for specific platforms, notably increasing the portability across systems. Besides, cross-compilation and specific tools are added to support a wide range of heterogeneous computing platforms such as CPUs, GPUs, ASICs. One of the objectives of LPDNN is to provide full support for reference platforms by providing:
Developer Platform Evironments (DPEs) to help the user employ a developer platform, including OS images, drivers, and cross-compilation toolchains for several heterogeneous platforms.
A dockerised and stable environment, which increases the reliability by encouraging the replication of results across platforms and environments.
Optimisation tools and computing libraries for a variety of computing embedded platforms that can be used by LPDNN’s inference engines to accelerate the execution of neural networks.
Deployment of AI applications on embedded devices¶
To be able to execute AI applications on a hardware platform, two elements are required:
An LPDNN AI application: It defines the class and structure of the AI application, the DNN models’ architecture and weights, its deployment configuration and the pre- and post-processing that it takes. LPDNN AI applications are platform-specific, although the same AI application can be executed on different HW platforms as long as the selected inference engine or backends are supported by the HW platform.
An LPDNN Deployment Package: Collection of tools, executables, libraries, inference engines and backends that allows the actual execution of the LPDNN AI application. The collection of libraries and binaries that are copied on the target platform for the execution of the DNN is called a runtime. The runtime dynamically loads an AI application and executes it based on its defined configuration. LPDNN’s deployment packages are platform specific as they contain the inferences engines and backends supported by the HW platform.
LPDNN AI application (AI App)¶
An LPDNN AI App is composed of the following files:
ai_app_config.json: This file is the main descriptor of an AI App. It defines the AI App’s components and their type, e.g., image_classification, object_clasification, face_recognition, audio_classification andsignal_processing, the type of pre- and post-processing as well as the inference engine to use to execute the DNN model. It also points to the model architecture and weights file.
ai_app.yml: This file defines the AI App metadata and license type. It also This describes the platform, runtime and challenge that the AI App was initially compiled for. This file is not used by the runtime, but by other deployment tools.
DNN model: A DNN model describes the model architecture and the trained weights. A DNN model may come on different forms based on the selected inference engine, e.g., model.json, model.param, model.bin or model.onnx.
LPDNN Deployment Package¶
An LPDNN runtime, contained within a deployment package, is the collection of binaries and libraries that are copied to the target platform for the execution of DNNs. Runtimes are composed of the following files:
Binaries: This folder contains the set of executables to start an AI App manually through different interfaces, e.g., ai-app-cli, ai-app-cli.py, http-worker.
Libraries: This folder contains the set of dynamic and static libraries that are included in LPDNN for a target developer platform. It includes the inference engines, the pre- and post-processing routines, backends, etc.
Solutions: This folder contains the bash scripts to start up an AI App automatically or remotely.
package.yml: This file defines the runtime name.
runtime.yml: This file contains metadata for the runtime and it is used to automatically start an AI App using the Bonseyes tools.
engines.yml: This file describes the available engines for within the runtime.
Deployment packages can be obtained by asking access to one of the BonsAPPS’s partner. LPDNN’s deployment packages can be found here.
Buy AI applications¶
As previously said, to be able to execute AI applications on a hardware platform, two components are needed:
LPDNN AI-Apps¶
AI-Apps can be bought from the BMP:
BMP AI-App landpage¶
To buy an AI app do the following:
Choose an AI app on the marketplace.
Press the buy button and follow the instruction.
Once the AI-App has been bought, you will see it in your dashboard.
Obtain an LPDNN Deployment Package¶
Deployment packages, including LPDNN runtimes, can be obtained by asking access to one of the BonsAPPS’s partner. LPDNN’s deployment packages can be found here.
Benchmark AI App¶
This guide assumes you have already performed the following:
Setup the local environment as explained in Prerequisites.
Setup the target hardware as explained in Setup platform section in the user guide and have the ${platformName_src} ${platformName_build} and ${platformName_config}.
Install python packages in the target board as explained in the Packages’s section.
Bought an AI-App in the BMP.
Once those steps are completed, change directory to the folder where you built your target platform during the Setup platform section, e.g., my-bonseyes-platform.
Donwload AI-App from BMP¶
Next, download an AI-App from the BMP by executing the following command (replace ${ai_app} by the name you would like to give to your AI-App):
bonseyes marketplace download-ai-app --output-dir ${ai_app}
A dialog will prompts asking you to choose the AI-App to download:
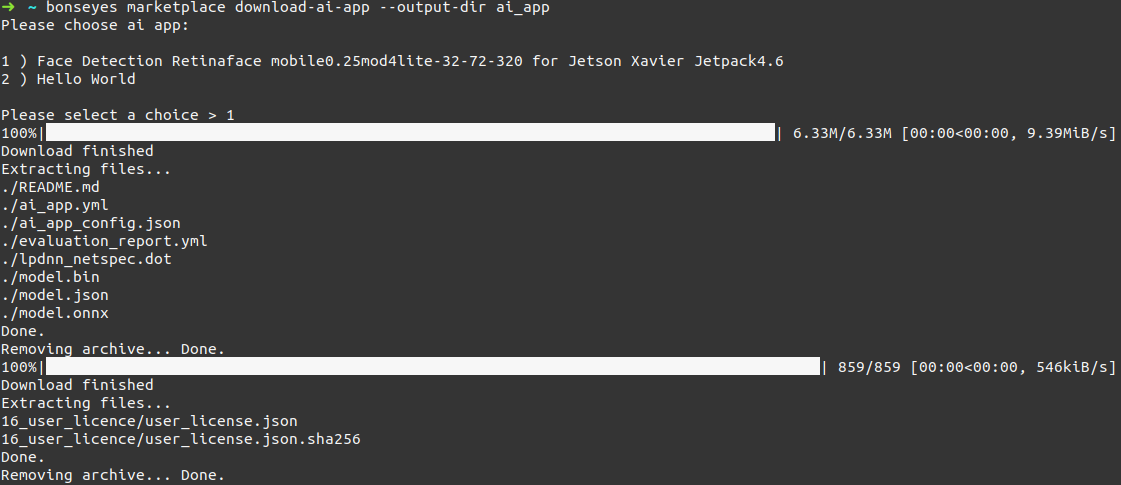
AI-App download¶
The ai app will be downloaded in the directory ${ai_app}
Download Deployment Package¶
Copy your LPDNN’s platform-specific deployment package in the same folder as the target platform and the AI-App. Next, decompress it (change ${deployment_package} by the name of your package):
cp ${deployment_package}.tar.gz my-bonseyes-platform
tar -xvf ${deployment_package}.tar.gz
Benchmark your AI-App you target HW¶
To benchmark an AI-App, your folder should contain the following elements:
${platformName_config}: target configuration coming from the DPE setup
${deployment_package}: downloaded from Gitlab
${ai_app}: downloaded from the BMP
To benchmark an AI-App, you need to execute the following command:
bonseyes ai-app benchmark-analyzer --target-config ${platformName_config} \
--ai-app ${ai_app} \
--deployment-package ${deployment_package} \
--dataset PATH/TO/DATASET_FOLDER \
[--number 20] \
[--filename ${FileName}]
For instance, to benchmark Squeezenet’s AI-App for Imagenet on the Jetson Nano platform looks like:
bonseyes ai-app benchmark-analyzer --target-config jetson_nano-jetpack4.6_config \
--ai-app squeezenet_v1 \
--deployment-package jetson_nano-jetpack4.6 \
--dataset /samples/ILSVRC2012 \
--number 20 \
[--filename benchmark.json]
This call will perform inference on twenty images from the ILSVRC2012 folder for squeezenet_v1 AI-App on the Jetson Nano platform with JetPack 4.6.
To store the benchmark in a file, add the –filename option and the metrics will be dumped in the named file in JSON format. If the file name option is enabled, prediction results will be automatically dump into results.txt*.
Demo AI-App¶
THIS SECTION IS WORK IN PROGRESS
This guide assumes you already have the done the following:
Setup the local environment as explained in Prerequisites
Setup the target hardware as explained in /pages/user_guides/platform/setup_platform
Obtained an AI app from the marketplace (see buy_ai_app) or cloned a repository containing an AI app or generated an AI app (see /pages/dev_guides/ai_app/generate_ai_app)
To start the demo an AI app you need to perform the following steps:
$ bonseyes ai-app start-demo --target-config target_config --ai-app ai_app
The demo will start on the target hardware.
To stop the demo the following command needs to be executed:
$ bonseyes ai-app stop-demo --target-config target_config --ai-app ai_app